Optimisation de l'emplacement et de l'allocation
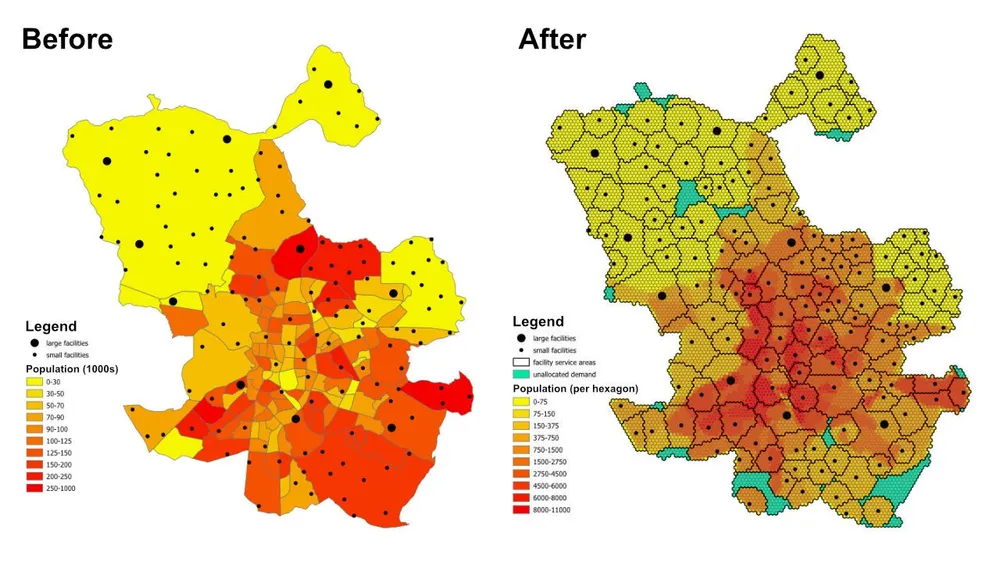
Cet exemple montre comment nous abordons un problème d’affectation et d’allocation d’emplacement important à l’aide de Python open source. Le flux de travail utilise des données anonymisées et montre comment nous préparons les entrées du modèle, construisons la matrice origine-destination, résolvons l’optimisation et exportons les sorties vers GeoJSON afin qu’elles puissent être examinées dans un logiciel SIG.
La question de planification est simple mais utile : compte tenu de la population de chaque quartier ou banlieue, de la capacité de chaque établissement et de la distance maximale que chaque établissement peut desservir, existe-t-il suffisamment d’établissements pour desservir l’ensemble de la population et, dans le cas contraire, quelles zones restent non attribuées en raison des contraintes actuelles ?
Ce que fait le modèle
Il s’agit d’un modèle d’affectation et d’allocation d’emplacement. Chaque emplacement de demande est représenté par un hexagone, chaque installation représente l’offre disponible et le modèle attribue chaque hexagone à une seule installation optimale tout en respectant les règles de distance de service et de capacité. Le même modèle de modélisation peut être utilisé pour les établissements de santé, les écoles, les banques, les magasins de détail ou d’autres réseaux de services où nous devons comprendre la couverture, les zones de service et les lacunes d’accès.
Le résultat n’est pas seulement un tableau d’affectations. Il peut également être transformé en couches de zones de service et de zones commerciales qui montrent quels emplacements sont potentiellement couverts par chaque installation, quelles zones de demande sont poussées vers une solution de secours non attribuée et comment le résultat change lorsque les capacités, les distances ou les objectifs sont ajustés.
Fonction objectif
Pour cet exemple, l’objectif est de minimiser la distance totale entre chaque hexagone de demande et l’installation qui lui est attribuée. Cela donne l’allocation la plus efficace selon les hypothèses actuelles. Le même cadre peut être réexécuté avec une fonction objectif différente si la question commerciale change. Par exemple, nous pouvons minimiser les coûts d’exploitation plutôt que la distance, minimiser le temps de trajet plutôt que la distance en ligne droite, ou rééquilibrer la demande afin que les installations les plus coûteuses reçoivent suffisamment de volume pour justifier leur profil d’exploitation.
Contraintes clés
- Chaque installation a une distance de service maximale, donc la demande en dehors de cette plage ne peut pas lui être attribuée.
- Chaque installation a des limites de population minimale et maximale, de sorte que la demande totale qui lui est assignée doit rester dans ses limites de capacité.
- Chaque hexagone de demande doit être affecté à un seul établissement.
- Si un hexagone ne peut être attribué à aucune installation réelle, il peut être attribué à une installation factice
unassignedafin que le modèle reste réalisable et que l’écart de couverture soit visible. - L’exemple utilise les distances euclidiennes entre les centroïdes hexagonaux et les installations pour un prototypage rapide, mais le même flux de travail peut être basculé vers de véritables itinéraires praticables si nécessaire.
Flux de travail
Le flux de travail comporte trois étapes principales :
- Convertissez la zone d’intérêt en un pavage hexagonal et dérivez la population de chaque hexagone.
- Générez la matrice origine-destination entre chaque hexagone de demande et chaque installation.
- Résolvez le modèle d’optimisation et exportez les résultats vers GeoJSON afin qu’ils puissent être examinés dans QGIS, ArcGIS Pro ou un autre logiciel de cartographie.
La pile d’implémentation comprend Python open source avec les sorties shapely, pyproj, sqlite3, pyomo, le solveur CBC et GeoJSON. Le modèle de préparation des données est délibérément modulaire, ce qui facilite le remplacement de la couche de demande, la modification des contraintes des installations, l’échange d’objectifs ou l’extension du modèle avec des règles métier supplémentaires.
Notes d’implémentation- PuLP a été testé à l’origine, mais pyomo a été choisi à la place car il gérait de manière plus fiable des modèles beaucoup plus grands.
- Le modèle a été résolu avec le solveur open source CBC, et cette approche a été adaptée à plus de 50 millions de variables de décision en moins d’une heure avec cette configuration.
- Pour des instances encore plus importantes, le gurobi peut être envisagé lorsque la licence le permet.
- L’écriture de sorties volumineuses dans GeoJSON peut prendre plus de temps que la résolution du modèle lui-même. Par conséquent, pour des séries de production plus importantes, il peut être plus efficace d’écrire directement dans une base de données.
- Un moyen pratique de construire des modèles comme celui-ci consiste à commencer avec de grands hexagones et des distances euclidiennes rapides tout en testant les contraintes, puis à passer à une tessellation plus fine et à des coûts de route plus réalistes une fois le comportement du modèle validé.
- Des contraintes supplémentaires peuvent être ajoutées progressivement, mais elles doivent être introduites avec précaution car chaque règle métier supplémentaire augmente le risque de rendre le modèle irréalisable.
Exemple de code source
Le code ci-dessous montre le flux de travail de bout en bout directement sur cette page.
1. generate_hexagons.py
0¤¤__
2. generate_origin_destination_matrix.py
1¤¤__
3. solve_the_model.py
2¤¤__